Perceived Reality is Not a Universal Constant
This started from a Reddit thread about Yann LeCun raising $1B to build AI that “understands the physical world” via world models. Someone in the comments made a reasonable point about predictive processing — your brain never has direct access to reality, it constructs a coherent model from noisy sensory input. Blind spots, saccades, retinal inversion. Standard stuff.
My response was simple:
“True, but not everyone can simulate things in their mind at all. Just like how some people can’t visualize things and also some people can’t dream. Being able to simulate how things should work with physics is not the same thing as visualization in thinking.”
The reply acknowledged it but kept going with the generalization. Which is the problem. Not the neuroscience — that part is fine. The problem is treating one mode of cognition as the universal description of human experience.
The Spectrum Nobody Mentions
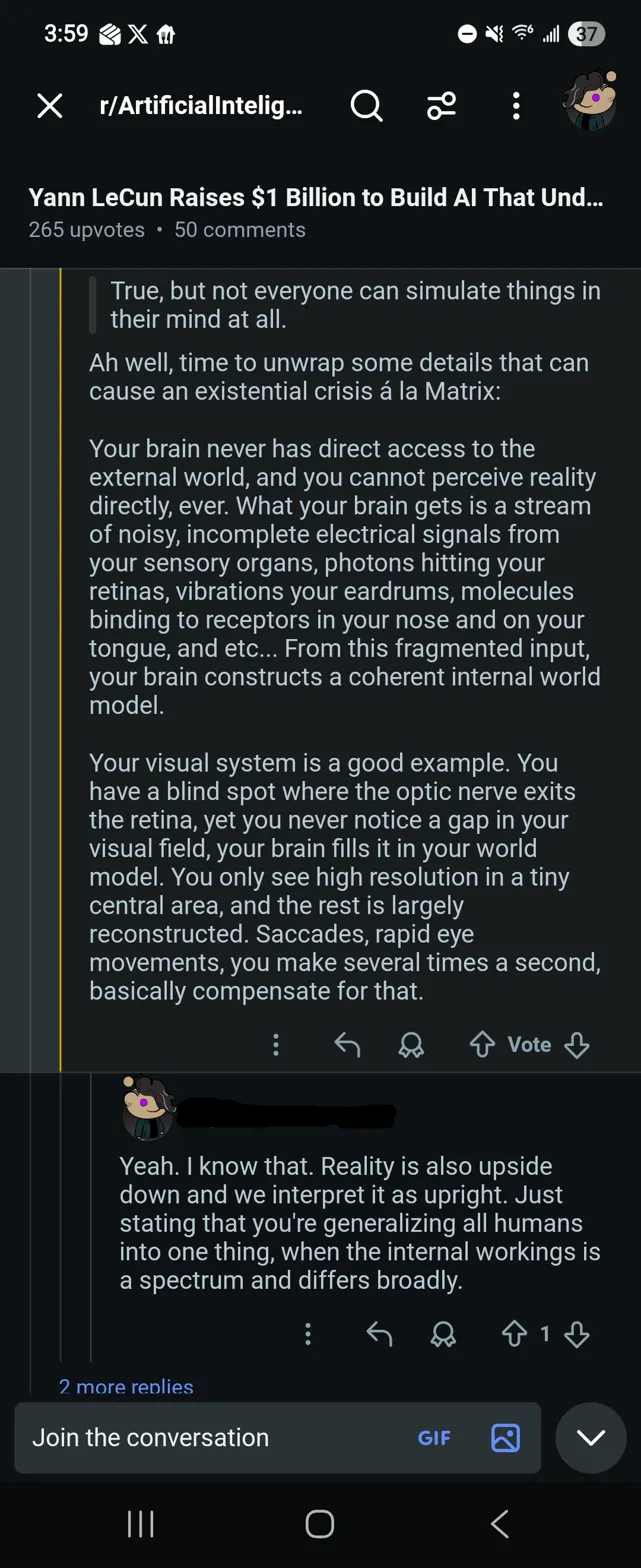
Predictive processing is real. Your visual system does fill in your blind spot. Saccades do compensate for low peripheral resolution. Retinal input is inverted and your brain corrects it automatically.
But that’s the subconscious layer — automatic, below access, not something you experience as computation. That part is pretty universal.
What isn’t universal is the deliberate layer. The conscious, voluntary simulation of physics, space, trajectory, force. That varies enormously between people and it’s not a smooth spectrum in every dimension — some of it looks closer to binary.
Aphantasia — the complete absence of voluntary visual imagination — affects roughly 2-5% of people. Those people still catch balls. They still navigate rooms. The automatic predictive layer works fine. The deliberate visualization layer is simply absent. If inner simulation were the substrate of cognition rather than one optional tool, aphantasia should be catastrophically disabling. It isn’t.
The same logic applies to physical simulation. The ball-throwing example from the thread assumes you can close your eyes and run a physics forward pass — feel the weight leaving your hand, predict the arc, anticipate the landing. Some people do that easily. Some do it partially. Some don’t do it at all and rely on sensorimotor feedback in real time instead.
Those are different cognitive profiles, not a single universal architecture.
Inverted Controls Are the Tell
Here’s a concrete example that doesn’t require neuroscience to understand.
In games, camera controls come in two flavors. Default: push stick up, camera goes up. Inverted: push stick up, camera goes down — as if you’re physically tilting your head back.
Inverted is actually closer to experienced physical reality. When you tilt your head back your visual field moves down relative to your body. Inverted controls map to that proprioceptive logic. Default is a learned remap that most games ship with because it’s more intuitive on a 2D screen.
Some people are native inverted. Some are native default. Switching between them is genuinely hard for most people — your spatial intuition has to remap in real time.
It took me three months to get used to inverted. By month five I was switching other games to inverted. By month six or seven I could move between both relatively fast depending on context.
That adaptability is interesting because it suggests the mapping isn’t hardwired — it’s a learned transform that can be maintained in parallel once both are sufficiently trained. Which is itself evidence that spatial processing is plastic and individually variable, not a single fixed architecture everyone shares.
There’s also research suggesting that switching between control schemes can improve aim and spatial tracking — the act of maintaining two reference frames and moving between them seems to sharpen the underlying spatial system rather than degrade it.
The Blindspot Generalization Fails Its Own Logic
The blindspot example is supposed to illustrate that your brain constructs reality rather than perceiving it directly. Fair enough.
But if you follow that argument you also have to acknowledge that the construction varies by the sensory apparatus doing the constructing. Mantis shrimp have 16 photoreceptor types. Dogs have 2. Humans have 3. The constructed reality is not the same across those systems — it’s shaped by what the sensor array can detect and how the neural architecture processes it.
Even within humans the variation is significant. Tetrachromacy — a fourth photoreceptor type — occurs in some women. Colorblindness alters the construction. Sensory processing differences in autism change what gets amplified and what gets filtered.
A better generalization than “your brain constructs a world model” would be: most nervous systems with sensory organs build internal representations shaped by their particular sensor array, processing architecture, and adaptive history. And those representations vary, sometimes dramatically, between individuals of the same species.
The brain is also extremely adaptive. The blind spot compensation isn’t a fixed program — it’s a learned fill that the visual system acquires and maintains. People who lose vision in one eye adapt. People with visual cortex damage develop compensatory strategies. The system is plastic in ways that the “you have a world model” framing tends to flatten.
What I Can Actually Do
Since this is a personal account I’ll be specific about my own profile.
I can spatially model and dynamically simulate physical scenarios with reasonable granularity. The ball-throwing example from the thread: I don’t just visualize the arc. I can separately model the ricochet — where it hits, what the surface absorbs, how the dispersal wave propagates, whether the rebound comes back at me and at what velocity. I can estimate how much force I need to apply to prevent a ricochet entirely vs. control where it goes.
Those are different computations. Trajectory is one thing. Ricochet geometry is another. Force calibration for a specific outcome is a third. I can run them somewhat independently.
Not everyone can do that. I know people who can visualize trajectory fine but have no intuition for force or dispersal. I know people who are excellent at real-time sensorimotor tasks but can’t pre-simulate anything offline.
The point isn’t that my profile is better. It’s that it’s different — and that the differences are specific and granular, not just “more or less simulation ability” on a single axis.
I can also visualize, though with variable resolution depending on what I’m modeling. A lossy trajectory arc, a number expression, a color, a noun — those come relatively easily. People and voices require more focus to hold clearly. The physical simulation capacity and the visualization capacity are not the same thing running at different speeds — they feel like genuinely separate systems.
So when I do a mental model of a concept, I’m doing the doing the “dynamical physical interface” of perse, if you show me a picture of a satellite network converging to complete saturation for a download by linking neighbors until finished? I will sometimes, often, automatically try to mentally model it. If I ask questions is corrections to the model, like does the radar move slowly while it updates? Those are clarifying questions and seeing if I’m understanding correctly.
In this case - the person I asked simply quoted the picture back at me and didn’t clarify that my assumption on the image was correct. Something like this for that section:
A concrete example of how this plays out in practice.
Someone shared a satellite constellation visualizer — a simulation showing how software updates propagate across a network of satellites via neighboring connections until full coverage is reached. Before asking clarifying questions I had already built a dynamic model of it: each transceiver as a node, packets passing bidirectionally to neighbors within line of sight, propagation spreading outward until saturation.
My clarifying question was whether the communication was synchronous or based on last known link position. That’s not a question someone asks when they don’t understand something. It’s a question someone asks when they’ve already built a model and want to verify a specific assumption about how it works.

The response I got was “you can also visualize it by looking at it.”
Which missed the point entirely. I had looked at it. I was describing what happened after, the automatic dynamic modeling that kicked in from the description alone, before I even saw the image. The questions weren’t confusion. They were calibration.
I had explicitly flagged that I wasn’t knowledgeable about satellites and invited correction before asking the question. That’s not imprecision; that’s epistemic transparency. The calibration question came after that disclaimer. The response wasn’t a correction. It was a complaint about my vocabulary.
Later in the same conversation, my word choice was flagged as the problem. Using “bifurcation” to mean branching propagation to neighboring nodes got treated as equivalent to calling Excel a programming language. That comparison is outdated even on its own terms: modern Excel with LAMBDA and recursion is effectively a functional, Turing-complete language (Microsoft Research on LAMBDA, recent formal analysis). One is imprecise vocabulary reaching for the closest available term. The other is a category error. The distinction matters, especially when someone has already told you they’re still building formal vocabulary. I rebutted with, I’m still learning and I was grasping at many different terms and settled on “bifurcation” due to it meaning bi and fork etymology. Splitting, branching, forking were all nested in that same hill. I had reached for bifurcation because I was thinking of one node, splitting to the nearest left and right neighbor - so 2-forking.
I was simultaneously running the dynamic model, visualizing the connection topology, and translating that internal representation into language in real time. The word choice wasn’t careless, in fact, it was the output of a live spatial-to-verbal translation. I reached for bifurcation because I was visualizing one node forking to its left and right neighbor: bi, two directions, branching. The etymology was doing the work I needed it to do in that moment.
The questions I ask when engaging with a new system aren’t a sign that I don’t understand it. They’re usually a sign that I’ve already understood it well enough to know which specific assumption I need to verify. Furthermore, in this interaction the other person explicitly claimed that case-based reasoning isn’t machine learning — which is just factually wrong. There is an entire literature treating CBR as a learning paradigm:
- Poole & Mackworth, Artificial Intelligence (2e), Ch.7 §7 — Case-based reasoning is presented alongside other learning approaches in an AI textbook, not as something outside of ML.
- A modern survey chapter on CBR in data science and ML pipelines (Springer chapter).
- Early foundational work from the IIIA group on CBR as a general problem-solving and learning framework (technical report, introductory notes).
- AAAI papers explicitly framing case-based approaches as part of machine learning and reasoning under uncertainty (AAAI paper).
- Additional chapters and articles on CBR in ML contexts (book chapter, IEEE article, Springer chapter).
So from my perspective, I wasn’t making up a new category. I was using the term in line with how the field itself uses it. The response was to shift the conversation to my word choice instead — and then to block me when the dynamic stopped going their way.
The Actual Problem with World Models
The thing that bothered me about the thread wasn’t the neuroscience. It was the destination.
LeCun’s $1B is going toward building AI that “understands the physical world” via learned world models. The implicit argument is that human-level physical understanding works by building an internal simulator and that replicating this in AI is the path to general physical reasoning.
But if the human case is already more variable and less simulation-dependent than that framing suggests, then the design target is wrong. You’re not trying to replicate a universal human world model because there isn’t one. You’re picking one cognitive profile — probably the one that researchers themselves happen to have — and treating it as the gold standard.
That’s not a world model. That’s a mirror.
The more useful question is what the minimal structural requirements are for an agent to navigate physical reality under changing reference conditions — not what the average human happens to do when they imagine throwing a ball.